
Hadoop大数据平台组件搭建系列 —— Hadoop完全分布式搭建(基于CentOS7.4)史上最简单的Hadoop完全分布式搭建 一站式解决!!!
简介
本篇介绍在 VMware+CentOS 7.4 环境上搭建 Hadoop 完全分布式。
使用软件版本信息:
jdk-8u144-linux-x64.tar.gz(提取码:qlft)
hadoop-2.6.0.tar.gz(提取码:zr2n)
Hadoop 集群分布如下:
| 编号 | 主机名 | namenode节点 | secondaryname节点 | datanode节点 | resourcemanager节点 |
|---|---|---|---|---|---|
| 1 | master1 | √ | √ | √ | |
| 2 | master2 | √ | |||
| 3 | slave1 | √ | |||
| 4 | slave2 | √ |
安装JDK
1. 解压jdk安装包至目标文件夹
powershell
tar -zxvf /opt/software/jdk-8u144-linux-x64.tar.gz -C /usr/local/src/2. 修改环境变量
powershell
vi /etc/profile在最后添加如下内容:
powershell
export JAVA_HOME=/usr/local/src/jdk
export PATH=$JAVA_HOME/bin:$PATH
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib3. 使环境变量生效、检查jdk版本验证jdk安装是否成功
powershell
source /etc/profilepowershell
java -version出现下图则jdk安装成功:

配置SSH免密登录
详情戳此篇:Linux中实现Hadoop各节点间的SSH免密登录
安装Hadoop完全分布式
解压安装包,并重命名
powershell
tar -zxvf /opt/software/hadoop-2.6.0.tar.gz -C /usr/local/scr/重命名:
powershell
mv hadoop-2.6.0/ hadoop修改环境变量,刷新环境变量
修改环境变量:
powershell
[root@master1 ~]# vi /etc/profile添加环境变量:
powershell
#.....hadoop......
export HADOOP_HOME=/usr/local/scr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin刷新环境变量:
powershell
[root@master1 ~]# source /etc/profile修改配置文件
hadoop-env.sh
添加jdk路径

yarn-env.sh
添加jdk路径(注意:去掉注释符#)
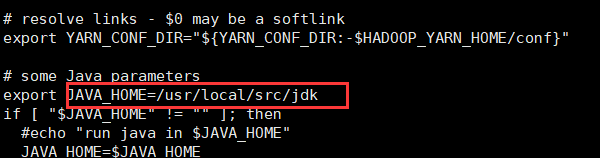
core-site.xml
powershell
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/scr/hadoop/tmp</value>
</property>
</configuration>hdfs-site.xml
powershell
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/scr/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/scr/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master1:9001</value>
</property>
</configuration>mapred-site.xml
先复制
mapred-site.xml.template为mapred-site.xml
powershell
cp mapred-site.xml.template mapred-site.xmlpowershell
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master1:19888</value>
</property>
</configuration>yarn-site.xml
powershell
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master1:8088</value>
</property>
</configuration>slaves
powershell
master2
slave1
slave2拷贝分发给子节点
- 拷贝分发环境变量给各子节点并刷新
powershell
[root@master1 hadoop]# scp -r /etc/profile master2:/etc/profile
...
[root@master1 ~]# source /etc/profile- 拷贝分发hadoop安装文件
powershell
[root@master1 ~]# scp -r /usr/local/scr/hadoop/ master2:/usr/local/scr/
...在主节点进行格式化
powershell
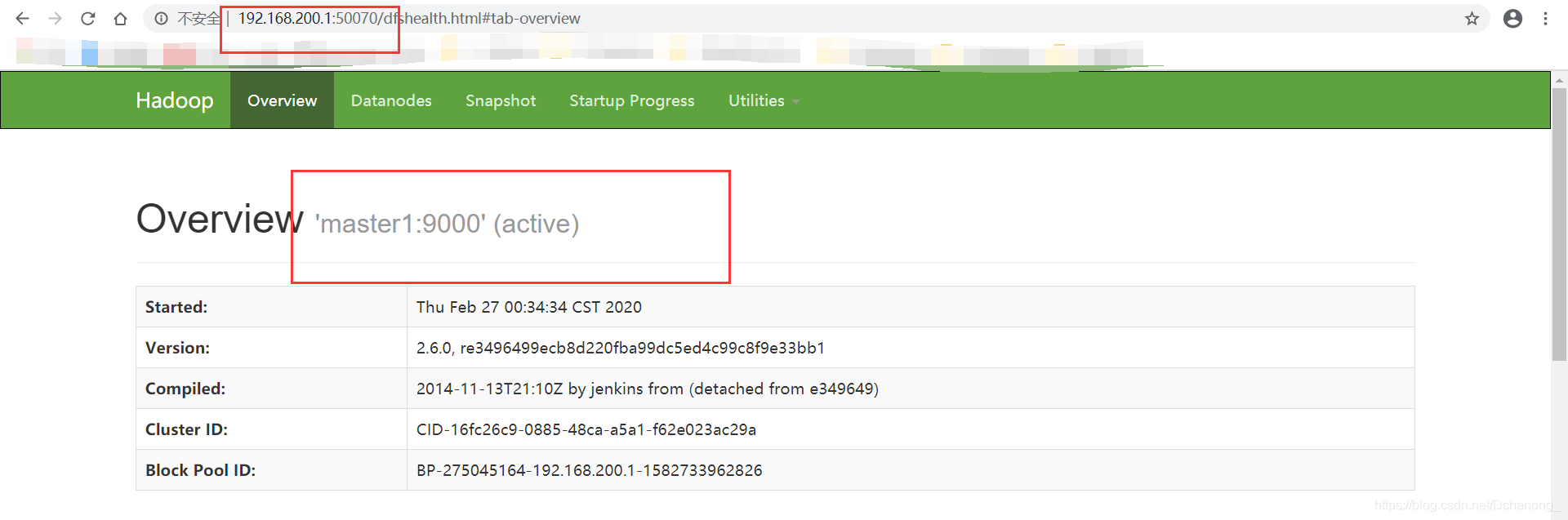
[root@master1 ~]# hadoop namenode -format验证安装成功
主节点:

子节点:

web端:
系列文章
Hadoop HA高可用+Zookeeper搭建 一站式解決方案!!!
Hadoop大数据平台组件搭建系列 —— Hadoop完全分布式搭建(基于CentOS7.4)史上最简单的Hadoop完全分布式搭建 一站式解决!!!
Hadoop大数据平台组件搭建系列 1—— Zookeeper组件配置
Hadoop大数据平台组件搭建系列 2 —— Sqoop组件配置
Hadoop大数据平台组件搭建系列 3 —— Hive组件配置
Hadoop大数据平台组件搭建系列 4 —— Kafka组件配置
Hadoop大数据平台组件搭建系列 5 —— MySQL组件配置(tar源码安装)